 KR Webzine Vol.155
KR Webzine Vol.155
- Dec. 2021
- Nov. 2021
- Oct. 2021
- Sep. 2021
- Aug. 2021
- Jul. 2021
- Jun. 2021
- May. 2021
- Apr. 2021
- Mar. 2021
- Feb. 2021
- Jan. 2021
- Dec. 2020
- Nov. 2020
- Oct. 2020
- Sep. 2020
- Aug. 2020
- Jul. 2020
- Jun. 2020
- May. 2020
- Apr. 2020
- Mar. 2020
- Feb. 2020
- Jan. 2020
- Dec. 2019
- Nov. 2019
- Oct. 2019
- Sep. 2019
- Aug. 2019
- Jul. 2019
- Jun. 2019
- May. 2019
- Apr. 2019
- Mar. 2019
- Feb. 2019
- Jan. 2019
- Dec. 2018
- Nov. 2018
- Oct. 2018
- Sep. 2018
- Aug. 2018
- Jul. 2018
- Jun. 2018
- May. 2018
- Apr. 2018
- Mar. 2018
- Feb. 2018
- Jan. 2018
- Dec. 2017
- Nov. 2017
- Oct. 2017
- Sep. 2017
- Aug. 2017
- Jul. 2017
- Jun. 2017
- May. 2017
- Apr. 2017
- Mar. 2017
- Feb. 2017
- Jan. 2017
- Dec. 2016
- Nov. 2016
- Oct. 2016
- Sep. 2016
- Aug. 2016
- Jul. 2016
- Jun. 2016
- May. 2016
- Apr. 2016
- Mar. 2016
- Feb. 2016
- Jan. 2016
- Dec. 2015
- Nov. 2015
- Oct. 2015
- Sep. 2015
- Aug. 2015
- Jul. 2015
- Jun. 2015
- May. 2015
- Apr. 2015
- Mar. 2015
- Feb. 2015
- Jan. 2015
- Dec. 2014
- Nov. 2014
- Oct. 2014
- Sep. 2014
- Aug. 2014
- Jul. 2014
- Jun. 2014
- May. 2014
- Apr. 2014
- Mar. 2014
- Feb. 2014
- Jan. 2014
- Dec. 2013
- Nov. 2013
- Oct. 2013
- Sep. 2013
- Aug. 2013
- Jul. 2013
- Jun. 2013
- May. 2013
- Apr. 2013
- Mar. 2013
- Jan. 2013
- Dec. 2012
- Nov. 2012
- Oct. 2012
- Sep. 2012
- Aug. 2012
- Jul. 2012
- Jun. 2012
- May. 2012
- Apr. 2012
- Mar. 2012
- Feb. 2012
- Jan. 2012
- Dec. 2011
- Nov. 2011
- Oct. 2011
- Sep. 2011
- Aug. 2011
- Jul. 2011
- Jun. 2011
- May. 2011
- Apr. 2011
- Mar. 2011
- Feb. 2011
- Jan. 2011
- Dec. 2010
- Nov. 2010
- Oct. 2010
- Sep. 2010
- Aug. 2010
- Jul. 2010
- Jun. 2010
- May. 2010
- Apr. 2010
- Mar. 2010
- Feb. 2010
- Jan. 2010
- Dec. 2009
- Nov. 2009
- Oct. 2009
- Sep. 2009
- Aug. 2009
- Jul. 2009
- Jun. 2009
- May. 2009
- Apr. 2009
- Mar. 2009
- Feb. 2009
- Jan. 2009
- Dec. 2008
- Nov. 2008
- Oct. 2008
- Sep. 2008
- Aug. 2008
- Jul. 2008
- Jun. 2008
- May. 2008
- Apr. 2008
- Mar. 2008
- Feb. 2008
01
January 2021
-
KR Inside
- KR releases new class rules for membrane-type LNG carriers
- KR grants AIP to HMD for 30,000m3 LNG carrier with prismatic IMO type-B tank
- KR holds a technical seminar to decide on measures to reduce greenhouse gas emissions
- KR grants ISO 45001 certification to KleanNara
- Cyber Security Newsletter for December 2020
- KR Survey Site News
- KR R&D Trends
- Technical News


As the demand for autonomous ship technology increases, the issue that ship condition inspection should also be digitized has emerged.
Object detection technology in the image has already been utilized in a variety of fields. Such as object recognition and detection, face recognition, place recognition, human posture recognition and detection, and etc. The technology for extracting a target from the image has been improved due to the performance of the computer and GPU computing is improved. The calculation of complex models has evolved rapidly as it becomes possible. Similarly, the field of inspection of ship conditions was developed for digitization as mentioned earlier. In particular, the focus was on the development of algorithms for detecting Cracks of various hull damage. KR developed and tested the Convolutional Neural Network (CNN) model using a deep-learning framework. Also the YOLOv5 model has been used to see the digitization potential of ship condition inspections.
To build the learning dataset, KR collected about 5,300 photos of hull damage, of which 629 photos of Cracks were filtered through the primary inspection. To solve the problem of insufficient number of training data, the number of data was increased by cutting and storing at regular sizes and intervals. In addition, most of the images are taken in a dark environment, so the images were re-distributed the pixel contrast value distribution through Histogram Equalization. Finally, the training datasets were configured differently depending on the trouble shooting purpose of the self-developed CNN model, the KR model and the YOLOv5 model.
|
|
Goal |
Labeling |
Size |
Learning image |
Verified image |
Total image |
|
KRmodel |
Defect type |
False |
256x256 |
Cracks:840 |
Cracks:240 |
2,160 |
|
YOLOv5 model |
Object detection and boundary box creation |
True |
512x512 |
Cracks:2,403 |
Other: 601 |
3,004 |
Table 1. Dataset specification
The KR model is a self-developed CNN model and is designed to solve the problem of estimating whether an image has cracks as it enters in the model. It consists of three Convolutional boxes for image-specific extraction and a Concatenate layer, Flatten, and Dense layer. As the number of filters increases from 32 to 128, 512, while reducing the number of Nodes in the Dense layer, it is finally connected by two results (Crack, Non-Crack). The activation function of ‘relu’ was used to prevent the Gradient vanishing problem, and the ‘softmax’ activation function was used for normalization of the last result to a value between 0 and 1.
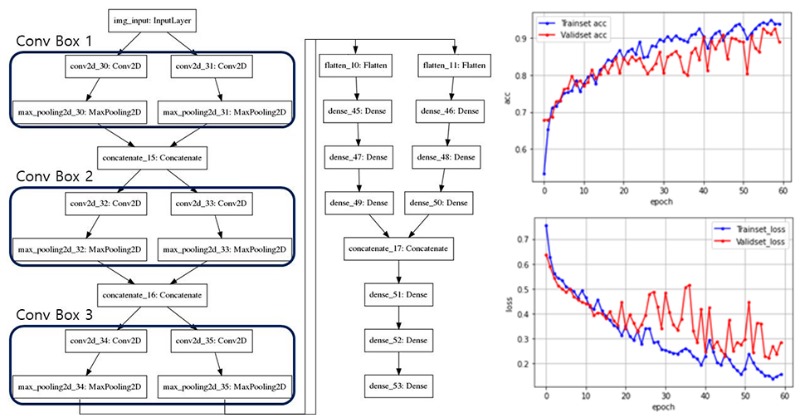
Figure 1. KR model structure(left), learning and validation Accuracy graph (upper-right) and Loss graph (lower-right)
The YOLOv5 model consists largely of Backbone and Head parts. Backbone is the part that extracts the Feature Map, and the Head is the part that seeks the position of the object based on the Feature Map. The final bounding box is generated using a preset Anchor Box. By default, each Feature consists of 9 Anchor Boxes using 3 Anchor Boxes at each size for size recognition (8px, 16px, 32px). It also extracts the characteristics of the image through a variety of layers, including Focus, BottleneckCSP, SPP, and Upsampling.
The graphic card used to calculate the KR model training was performed with one Quadro RTX8000. Since the size and capacity of the image was not large, the batch size of the photo entering was the 128 for an Epoch, Learning Rate was set to 1x10-4. A total Epoch was set to 60 through the quickly grasping learning trends and judging by the minimum number of learnings in consideration of computational speed. In the final 60th Epoch, learning Accuracy of 0.9393, Learning Loss of 0.1563, Verification Accuracy of 0.8896, and Validation Loss of 0.2857 were recorded. Accuracy of 0.8583 was recorded as a result of inferring and evaluating using weighted values obtained from 240 crack and other defect images that were not used for learning and validation.
The graphic cards used to calculate the YOLOv5 model training were four Quadro RTX8000s. Batch size of 64, learning Rate of 1x10-2 , and a total number of 1,000 Epochs were set to learning, taking in to account the characteristics and learning tendencies of the model. The graph showed that the precision is slightly increased after 10 minutes of learning, and then goes down after 80 minutes of learning. The result confirmed that the training data was over fitted and the precision of the data that was not involved in the training was insufficient. In other words, there is not enough variety to fully learn the characteristics of crack defect photography. In the graph, you can see how the number of recall increases after 80 minutes of training. According to the Confusion Matrix, the number of True predictions that the data is actual True (TP), and the number of True predictions that the data is actual False (FP) increases, the accuracy of the verification data will go down. That is, it can be seen in the Trade-off relationship according to a limited number of verification data. Finally, using the verification data 601 photos, the precision was recorded 0.713, and the recall was 0.5
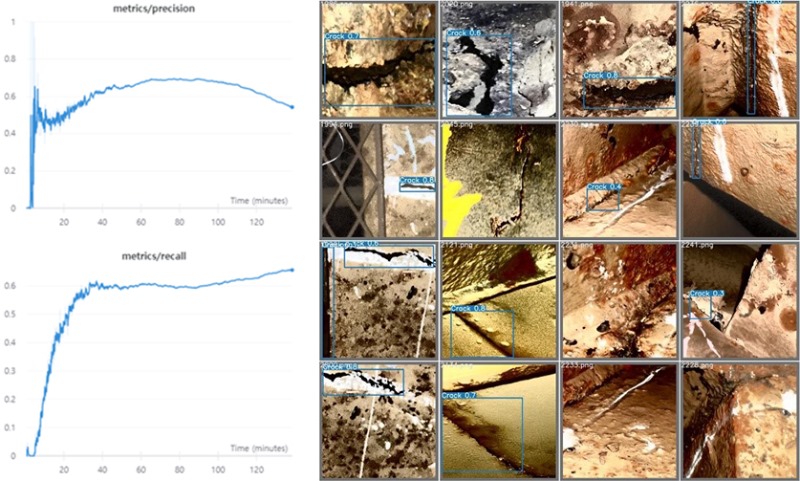
Figure 2. YOLOv5 model Precision graph (upper-left) and Recall graph (lower-left), crack detection (boundary-box) example (right)
After learning, KR evaluated performance by using a simple image data prediction, KR model for classification purposes, and YOLOv5 to determine the ability to create bounding boxes through object detection. It is difficult to objectify the performance indicators of two models with different purposes of troubleshooting, but both models were able to determine the results that matched their original purposes. However, the results showed that the model is over-fitted with the training data due to the limitations of the number and quality of the data. This means that improvements will be needed by increasing the number of data, building quality datasets, comparing various CNN models, extending the model through analysis, and applying feedback through real-world testing in the field.
